GPT#
GPT 的全称为 Generative Pre-training Transformer。
1、模型结构与预训练#
1.1 GPT与ELMo的区别#
-
网络结构上:ELMo 使用浅层(2层)BiLSTM 网络,然后虽然 BiLSTM 网络是双向的,但是其两个方向是相互独立的。GPT 使用深层(12层)Transformer 网络,然后 Transformer 是能够同时看到两个方向的文本的。
-
下游任务时:ELMo 是将多个层的输出都用上,并且根据任务的不同,每层的权重不同。GPT 是不同的下游任务都是用模型中最后一层 Transformer 的输出。
1.2 模型结构与预训练#
... 略 ...
2、有监督微调#
先放上原论文中经典的图:
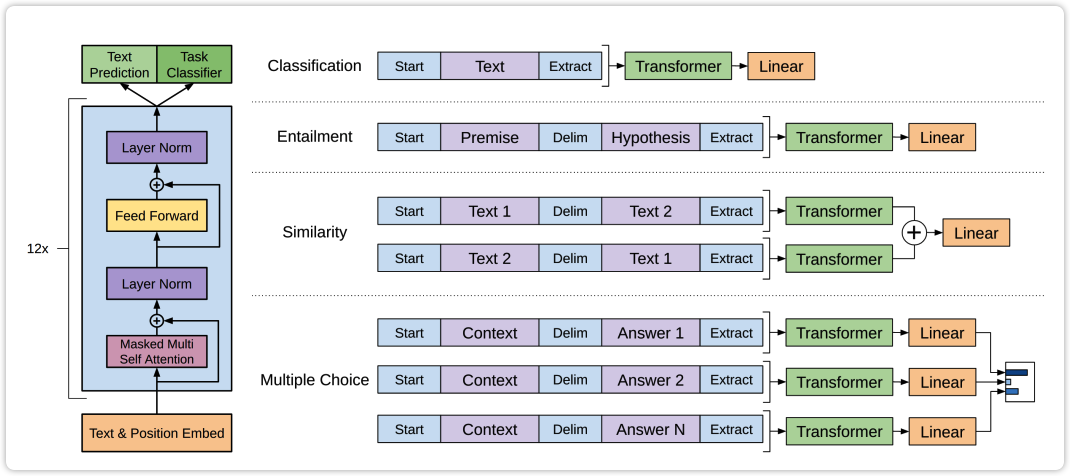
分类任务:Bert模型如果要做 sequence classification 任务,其需要给每条样本专门增加 [CLS] 这个token,使用该token对应的向量做分类。而GPT则不需要新增一个特殊的token,它是直接使用整个输入token序列的下一个位置预测的向量做分类。
自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
问答和常识推理:将 n 个选项的问题抽象化为 n 个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
3、代码操作细节#
3.1 训练时偏移一位的实现#
从上文已经知道GPT的训练是已知前面的字符,预测后面的字符,对应的公式为:p(x_1,...,x_n)=\prod_{i=1}^n p(x_i|x_1,...,x_{i-1}),那么这个根据前面的字符预测当前字符在代码中是如何实现的呢?下面分别说明项目 huggingface/transformers 和项目 karpathy/minGPT 中是如何实现的。
先说下大体的思路,实现上述公式的代码有两种方式:
-
数据载入时 "input_ids" 和 "labels" 完全相同,然后在模型计算loss时做一下偏移,项目 huggingface/transformers 中就是这样做的;
-
数据载入时就对 "input_ids" 和 "labels" 做好偏移,比如 "input_ids" 为
1 2 3 4 5 6 7 8 9,而 "labels" 为2 3 4 5 6 7 8 9 <eos>。项目 karpathy/minGPT 采用的是这种方式。
huggingface/transformers 项目#
该项目中,其在数据处理部分获取 "input_ids" 和 "labels" 时的代码如下所示(官方代码链接):
def group_texts(examples):
... ...
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
上述代码主要看倒数第二行,可以看到 "labels" 的值是直接copy的 "input_ids",所以在此时 "input_ids" 与 "labels" 肯定是相同的。
然后再看一下在该项目中GPT2模型计算loss时的代码,如下(官方代码链接):
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(lm_logits.device)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
上述代码中,lm_logits 表示模型前向传播输出的结果,其shape为[batch_size, seq_len, vocab_size];labels 就是 copy 自 "input_ids" 的,其shape为[batch_size, seq_len]。主要看上述代码的第6行和第7行可知,其对 labels 去掉了第一个token,对 lm_logits 去掉了最后一个token,这样也就实现了根据前面的token预测下一个token了。
karpathy/minGPT 项目#
该项目是实现了一个最简版的GPT,主要目的是方便新手理解GPT是如何实现的。也由于该项目是一个玩具项目,所以其训练数据并不是从文件中读取的,而是随机生成的,代码如下(官方代码链接):
def __getitem__(self, idx):
... ...
# the inputs to the transformer will be the offset sequence
x = cat[:-1].clone()
y = cat[1:].clone()
# we only want to predict at output locations, mask out the loss at the input locations
y[:self.length-1] = -1
return x, y
上述代码中 cat 是随机生成的 token 序列,x 是 "input_ids",y 是 "labels"。可以看出其操作与huggingface的transformers中模型的前向推理时所作的操作是完全相同的。
3.2 推理代码#
由于项目 karpathy/minGPT 中只实现了最核心的功能,非常利于理解原理,所以还是使用该项目中的代码。推理部分的代码如下(官方代码链接):
def generate(self, idx, max_new_tokens, temperature=1.0, do_sample=False, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.block_size else idx[:, -self.block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = self(idx_cond)
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, top_k)
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# either sample from the distribution or take the most likely element
if do_sample:
idx_next = torch.multinomial(probs, num_samples=1)
else:
_, idx_next = torch.topk(probs, k=1, dim=-1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx
该代码中是比较简单的,比如这里没有遇到某个结束字符就中断for循环的逻辑。
3.3 解码时如何减少模型的重复输出#
在使用生成式模型时,比较常见的一个现象就是模型经常会输出重复的文本。然后 openai 的 API 中有两个参数 presence_penalty 和 frequency_penalty 用于在解码时控制允许在多大程度上输出重复文本(官方解释文档:Frequency and presence penalties)。
该方法的大概思路是:根据每个 token 是否已经被选中过,以及被选中过的频次,对当前位置的模型输出的 logits 做一些修改。使那些出现过、或者出现过多次的 token 的概率降低。计算公式如下:
mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
其中:
-
mu[j]:表示模型在 token 序列的位置 j 处输出的 logits; -
c[j]:表示在 token 序列的位置 j 之前每个 token 分别已经被选中的频次; -
float(c[j] > 0):当c[j] > 0为 true 时该值 1 ,否则为 0 ; -
alpha_frequency:可配置的超参数之一; -
alpha_presence:可配置的超参数之一;
可以看出参数 alpha_presence 只关心某个 token 是否在之前出现过,参数 alpha_frequency 还会关心某个 token 在之前出现过的频次,所以这两个参数可以结合使用。一般来说,如果想轻度抑制模型生成重复文本,可将这两个参数设置为 0.1 到 1 之间;如果想非常严格的控制生成重复文本的问题,可以将这两个参数设置为 2。