ALBERT#
ALBERT 的全称为 A Lite BERT。所以从名字可以看出,这个模型的目的是想搞一个比 Bert 更小、更轻量级的模型。
这个模型相比于 Bert 在三个方面做了修改,下面先描述修改哪三个方面,最后放上和 Bert 对比的效果。
1、对 Embedding 层的参数做因式分解#
符号说明:将 embedding 层向量的维度定义为 E,将 transformer 层中向量的维度定义为 H,在 Bert 中 E 与 H 是相等的。
在 Bert 模型中,embedding 层的向量维度与 transformer 层的向量维度是相同的,该问作者认为这两者没有必要相同,原因有二:
-
一般来说,模型不同的层学到的信息是不同的,按照 ELMo 模型中的分析,靠近输入的层学到的是语法信息,离输入较远的层学到的是语义信息。在本文中作者认为,embedding 层中学到的向量应该是没有上下文(context)信息的,而 transformer 层中学到的向量是包含上下文(context)信息的。所以从这个角度来说由于需要存储更复杂的上下文(context)信息,transformer 层中的向量维度 H 应该要远大于 embedding 层中的向量维度 E。
-
另外一个方面则是因为 embedding 的参数量在整个模型的参数量中占比是比较高的,而 embedding 层在训练时更新的又比较稀疏(这个结论是哪来的?)所以减少 embedding 层的参数量是合理的。
基于上述两个原因,本文提出的方法是 embedding 权重矩阵的维度是 V * E(这里的 E < H ),得到 embedding 的向量之后再通过一个 E * H 的权重矩阵投影到 transformer 层的隐空间上。改进前后 embedding 层的参数量分别为:
- 改进前的参数量:V * E,这里 V 表示 vocab 的个数,并且 E 与 H 相等。以 bert-base 模型为例,参数量为 21128 * 768 = 16226304,约为 16M;
- 改进后的参数量:V * E + E * H,这里 E 是小于 H 的。还是以 bert-base 模型为例,假设 embedding 层的向量维度 E 为 128,参数量为 21128 * 128 + 128 * 768 = 2802688,约为 2.8M;
可以看出 embedding 层的参数量大幅减少。
下面简单介绍一下 embedding 层中的参数量在整个模型的参数量中的占比(以 bert-base 为例进行分析)。
\quad
bert-base 的模型结构为:vocab 总共有 21128 个,隐藏层维度为 768,12 层 transformer,multi-head attention 中是 12 个 head,每个 head 的隐层维度是 64。官方论文中总参数量为 110M。
\quad
估计 Bert 模型的参数量:
\quad
embedding 层:总共 21128 个 vocab,每个向量的维度是 768,总参数量为 21128 * 768 = 16226304
multi-head attention 层:这一层带有参数的有三部分,分别为 QKV 的权重矩阵、dense 层、Layer Norm层,分别计算
- QKV 的权重矩阵:每个权重矩阵的输入向量的维度为 768,有 12 个 head,每个 head 的隐层维度是 64,则参数量为 768 * 64 * 12 = 589824,三个权重矩阵的参数量就是再乘以3,即 768 * 64 * 12 * 3 = 1769472
- dense 层:这个比较简单,直接就是 768 * 768 = 589824
- Layer Norm层:这一层里面不是矩阵乘法,而是向量的相应位置的元素相乘,所以 \gamma 和 \beta 的参数量是 768 + 768 = 1536
FFN 层:这一层包含两个 dense 层,这两个 dense 层先将维度由 768 升到 3072,再由 3072 降到 768,然后接一个 Layer Norm 层,所以参数量为 (768 * 3072) + (3072 * 768) + (768 + 768) = 4720128
总共12个 transformer 层:这个就是 multi-head attention 层的参数量加上 FFN 层的参数量,然后乘以 12 即可,每层 transformer 的参数量 1769472 + 589824 + 1536 + 4720128 = 7080960,总共 12 层的参数量 7080960 * 12 = 84971520
如果是预训练的话在 12 层 transformer 之后还会有分类器,这部分就忽略不计算了。
最后汇总 embedding 层和 12 个 transformer 层的总参数量: 16226304 + 84971520 = 101197824,也就是说大概 101M 的参数量,相比于官方所说的 110M,这其中的差距主要包括最后的分类器层,以及上述计算过程中都没有考虑偏置项(bias)。
最后回到重点:看一下 embedding 层的参数量占总模型参数量的比例,16226304 / (16226304 + 84971520) = 16.0%,再对比一下每个 transformer 层的参数量占总模型的参数量的比例,7080960 / (16226304 + 84971520) = 7.0%,所以 embedding 层的参数量相当于两个 transformer 层的参数量还多,这也是本文中认为 embedding 层的参数量可以缩减的原因。
2、跨层参数共享#
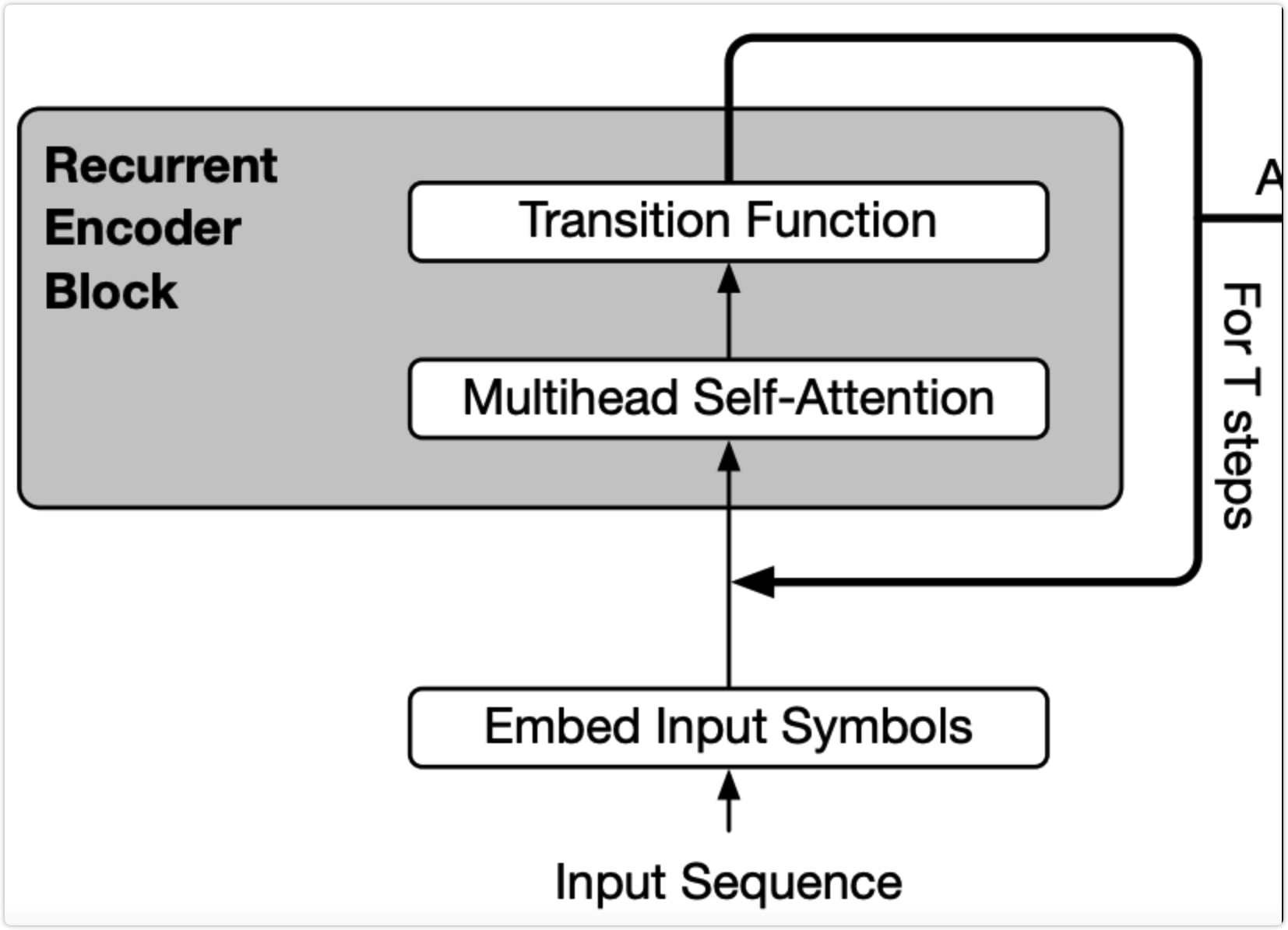
这部分的做法很容易理解,就是所有的 transformer 层共享相同的参数,也就是说实际上只有一个 transformer 层的权重,然后会多次经过这个 transformer 层。比如 bert-base 有 12 层 transformer,改成 albert 就是数据会经过同一个 transformer 层 12 次,如下图:
| 图1: |
|---|
 |
3、将 NSP 任务换成了 SOP 任务#
SOP 的全称为 sentence order prediction。
在该文章之前已经有些文章发现,bert 的论文中的 NSP 任务没有什么作用。该论文任务 NSP 任务之所以没有作用,是因为其太简单了,所以在其基础上设计了一个难度更高的新任务,也就是 SOP 任务。SOP 任务就是预测两句话有没有被交换过顺序。
4、新模型收益#
4.1 运行速度和显存消耗方面#
关于显存消耗方面,收益主要来自于第 2 章节中提到的跨层参数共享,本来需要 12 层的权重,现在直接变成 1 层了,需要的显存大幅减少。另外第 1 章节中提到的减少 embedding 层的参数量也能显著减少显存的消耗。
关于运算速度方面,可以看出在最耗时的 transformer 的计算部分丝毫没有减少,本来需要计算 12 层 transformer 的话,新模型还是需要计算 12 层。论文中所提到的速度提升是因为使用相同的数据量做预训练时,由于模型参数量变少,占用的显存变小,每个 batch 中就可以方更多的数据,由此导致的训练时间减少。但如果要对一天样本进行推理,那么速度上是相同的。
4.2 效果方面#
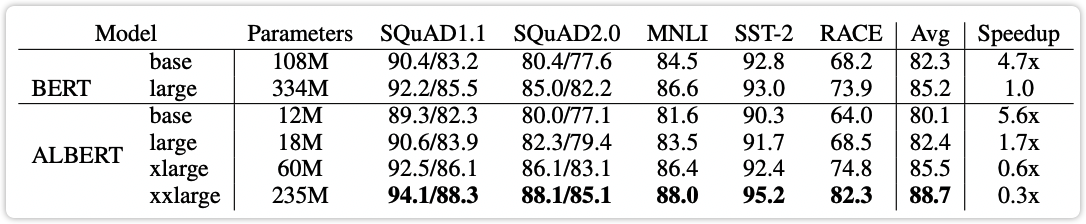
由原论文中提供的下图可以看出:ALBERT-base 相比于 BERT-base 降了 2.2%;ALBERT-large 相比于 BERT-large 降了 2.8%。所以参数量的大幅减少是以损耗一定的模型效果为前提的,具体要选择哪种模型,还要结合具体任务。