ZeRO#
由于 ZeRO 本质是数据并行,所以需要了解 DDP 的原理之后才能够比较容易的理解 ZeRO,关于 DDP 的说明文档见:DDP
在说明时假设显卡数量为 N,模型的参数量为 \Psi。下述的图片都是以两张显卡为例绘制的。
下面说明一下 DDP、ZeRO1、ZeRO2、ZeRO3 这几种不同的技术具体是如何操作的。这里的重点是何时做数据同步,训练过程主要有 "前向传播"、"反向传播"、"优化器更新权重参数" 这三部分,下面在描述时也是按照这三部分进行描述。
参数量:模型参数量是指一个神经网络或机器学习模型中可以进行学习和调整的参数的数量。这些参数包括权重(weights)和偏置(biases),它们在训练过程中会不断地更新以优化模型的性能。
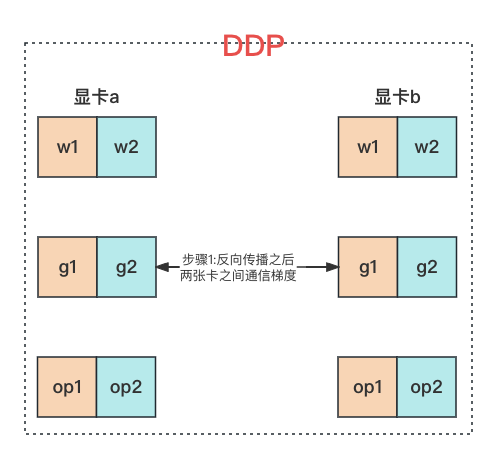
1、DDP#
模型的权重 w、梯度 g、优化器状态 op 都是在每张显卡上存储完整的一份,每张显卡上是不同的 mini-batch 的数据。训练时:
- 前向传播:每张显卡使用自己的 mini-batch 的数据做前向传播;
- 反向传播:反向传播完成,求出来梯度之后,使用 Ring AllReduce 方法将梯度同步到所有的显卡上;
- 优化器更新权重参数:每张显卡上拿到总的梯度之后,每张显卡自己使用自己的优化器更新自己的权重参数;
所以 DDP 方法仅在反向传播完成之后有一次数据传输,需要传输的是梯度,梯度的参数量等于模型权重的参数量,为 \Psi。
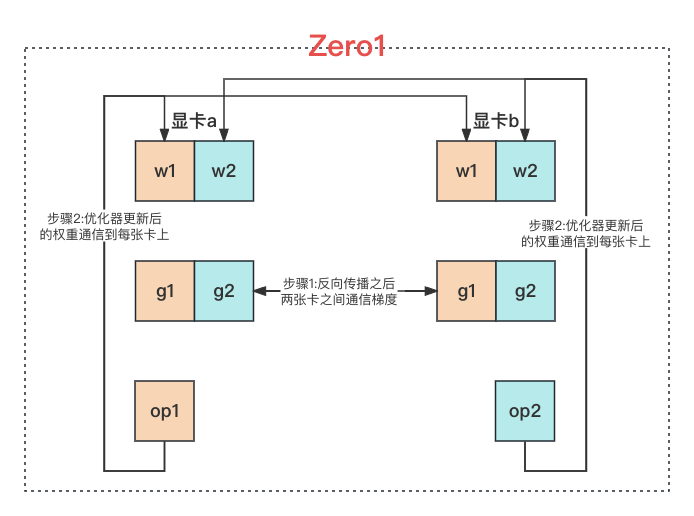
2、ZeRO1#
模型的权重 w、梯度 g 都是在每张显卡上存储完整的一份,优化器状态 op 则是每张显卡上存储 1/N,每张显卡上是不同的 mini-batch 的数据。训练时:
- 前向传播:每张显卡使用自己的 mini-batch 的数据做前向传播;
- 反向传播:反向传播完成,求出来梯度之后,使用 Ring AllReduce 方法将梯度同步到所有的显卡上;
- 优化器更新权重参数:每张显卡上可以拿到总的梯度,但是每张显卡上只有 1/N 的优化器状态,所以每张显卡更新自己那 1/N 的权重参数,更新完成之后使用 Ring AllReduce 方法将权重参数同步到所有的显卡上;
由上可见 ZeRO1 方法:在反向传播之后有一次数据传输,需要传输的是梯度,为 \Psi;在优化器更新完权重参数之后也有一次数据传输,此时传输的是更新后的参数,为 \Psi。所以 ZeRO1 需要同步的参数量为 2 \Psi。
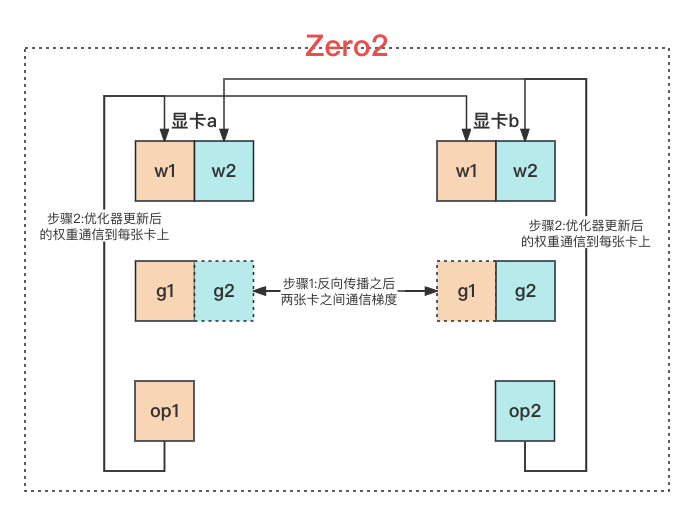
3、ZeRO2#
模型的权重 w 是在每张显卡上存储完整的一份,梯度 g 和优化器状态 op 则是每张显卡上存储 1/N,每张显卡上是不同的 mini-batch 的数据。训练时:
- 前向传播:每张显卡使用自己的 mini-batch 的数据做前向传播;
- 反向传播:由于每张显卡并不是存储所有的梯度,所以反向传播求梯度的过程并不是一下子直接计算完成的。而是每计算出一小部分梯度之后就和其他的显卡同步一下,同步时还是使用 Ring AllReduce 方法。当前显卡只保存自己那 1/N 的梯度,其他部分的梯度由其他显卡存储;
- 优化器更新权重参数:每张显卡上仅存储有自己的那 1/N 的梯度,优化器状态也是仅有自己的那 1/N,有了这两部分信息之后,每张显卡就可以更新自己的那 1/N 的权重参数,更新完成之后使用 Ring AllReduce 方法将权重参数同步到所有显卡上;
由上可见 ZeRO2 方法:在反向传播的过程中有一次数据传输,需要传输的是梯度,为 \Psi;在优化器更新完权重参数之后也有一次数据传输,此时传输的是更新后的参数,为 \Psi。所以 ZeRO2 需要同步的参数量为 2 \Psi,与 ZeRO1 需要同步的参数量完全相同。
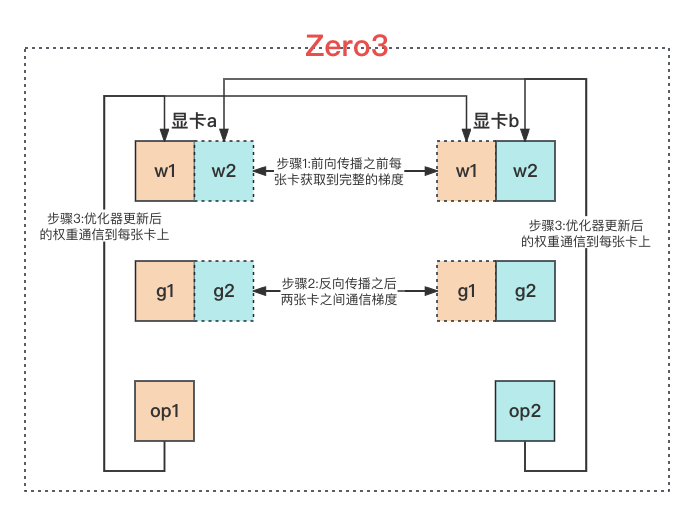
4、ZeRO3#
模型的权重 w、梯度 g 和优化器状态 op 都是每张显卡上存储 1/N,每张显卡上是不同的 mini-batch 的数据。训练时:
- 前向传播:由于每张显卡上只存储了 1/N 的模型权重参数,所以无法直接进行前向传播。在前向传播过程中,当需要使用某部分模型的权重参数时,先通过 Ring AllReduce 方法从其他卡中把这部分的权重参数获取到之后,再做前向传播的运算;
- 反向传播:由于每张显卡并不是存储所有的梯度,所以反向传播求梯度的过程并不是一下子直接计算完成的。而是每计算出一小部分梯度之后就和其他的显卡同步一下,同步时还是使用 Ring AllReduce 方法。当前显卡只保存自己那 1/N 的梯度,其他部分的梯度由其他显卡存储;
- 优化器更新权重参数:每张显卡上仅存储有自己的那 1/N 的梯度,优化器状态也是仅有自己的那 1/N,有了这两部分信息之后,每张显卡就可以更新自己的那 1/N 的权重参数,更新完成之后使用 Ring AllReduce 方法将权重参数同步到所有显卡上;
由上可见 ZeRO3 方法:后两个阶段与 ZeRO2 是完全相同的,只是在前向传播阶段,需要通信一次模型的权重参数,为 \Psi。在反向传播的过程中有一次数据传输,需要传输的是梯度,为 \Psi;在优化器更新完权重参数之后也有一次数据传输,此时传输的是更新后的参数,为 \Psi。所以 ZeRO3 需要同步的参数量为 3 \Psi,其是 ZeRO1 和 ZeRO2 所需通信量的 1.5 倍。