LLaMA#
1、该篇论文的重点#
-
推进开源,不仅将训练好的模型开源,在预训练时使用的训练数据也仅使用开源数据,这样后来人能够完全的复现该模型;
-
探究相对小一点的模型,加上相对比较大的数据集,所取得的最终效果;模型较小的话,下游使用时成本较低。
2、Approach#
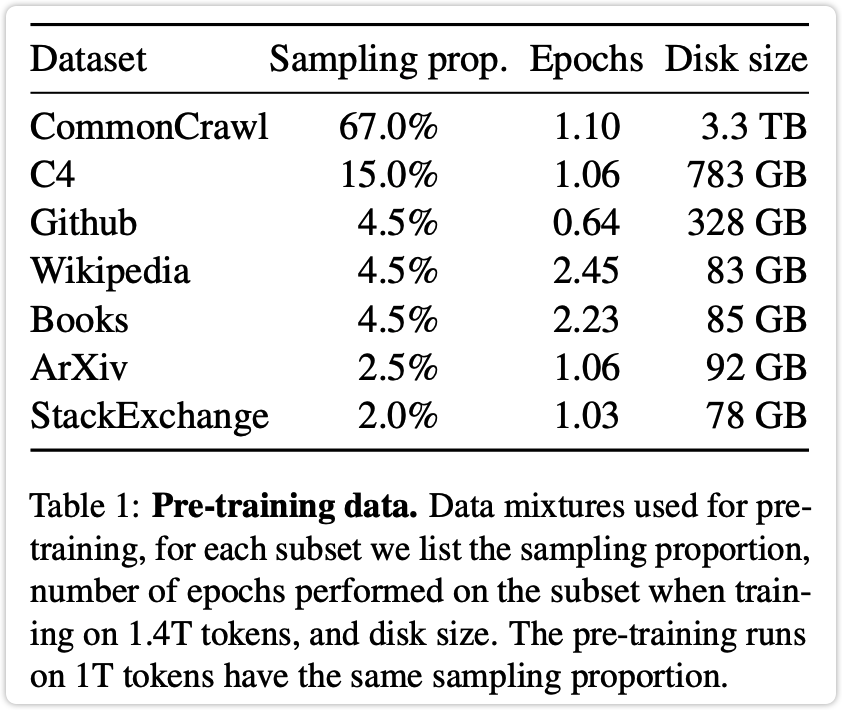
2.1 使用的数据#
用了以下数据集,全部开源可获取。
2.2 Architecture#
- Pre-normalization:即将本来放在 MH Attention 和 FeedForward 后面的 LayerNorm,放到了这两层之前;
- 规一化函数使用 RMSNorm;
- 激活函数使用 SwiGLU;(来自于 PaLM);
- 位置嵌入层为 Rotary Embeddings,(来自于 GPTNeo);
各超参数信息:
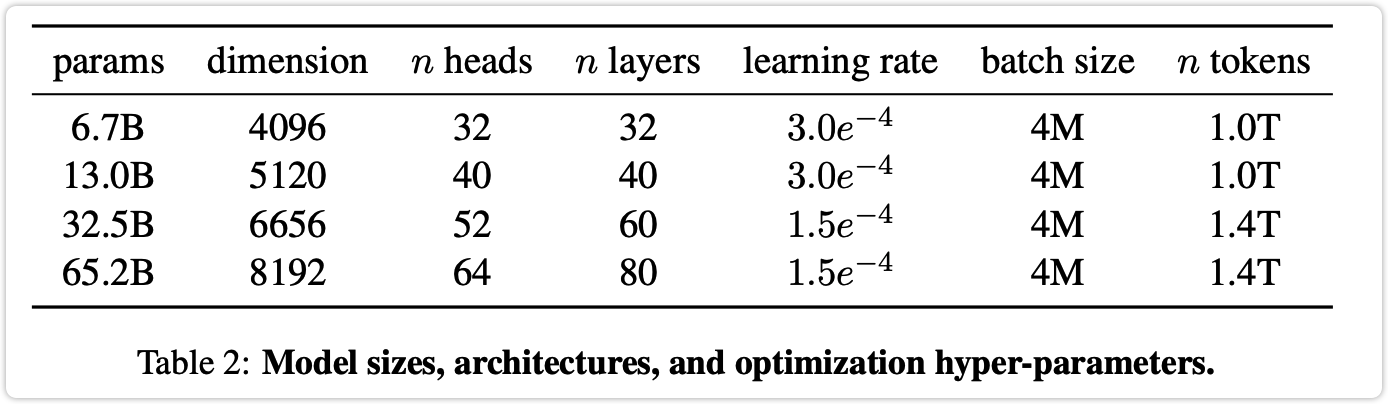
2.3 提高训练速度方面使用的技术#
- xformers 库中的优化版的多头注意力,至于优化了什么原文是:not storing the attention weights and not computing the key/query scores that are masked due to the causal nature of the language modeling task;
- 加入了减少部分重复计算的方法(来源:Reducing Activation Recomputation in Large Transformer Models)
3、效果#
比较对象#
非开源的 GPT-3、Gopher、Chinchilla 和 PaLM,还有开源的 OPT 、GPT-J 和 GPTNeo。
比较的任务#
- 常识推理
- 闭卷问答
- 阅读理解
- 数学推理
- 代码生成
- MMLU(massive multitask language understanding:https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu)
效果说明#
待补充
4、Instruction Finetuning#
不是这篇论文的重点,做的很粗糙,略;
偏见问题与能耗问题#
略