实体关系抽取之TPLinker#
1、关系抽取的难点#
暴漏偏差问题: 指在训练阶段是gold实体输入进行关系预测,而在推断阶段是上一步的预测实体输入进行关系判断;导致训练和推断存在不一致。
关系抽取的重叠问题:
- SEO(SingleEntityOverlap):一个实体出现在多个关系三元组中;
- EPO(EntityPairOverlap):一个实体pair有多种关系;
2、关系抽取的一些做法#
关系抽取的一些做法:
-
pipeline方法:
-
先抽取实体,然后对实体对进行分类;
-
先抽取主语,再抽取谓语和宾语;
-
先抽取关系,再抽取主语和宾语;
-
-
联合抽取方法
3、TPLinker#
3.1 编码方式#
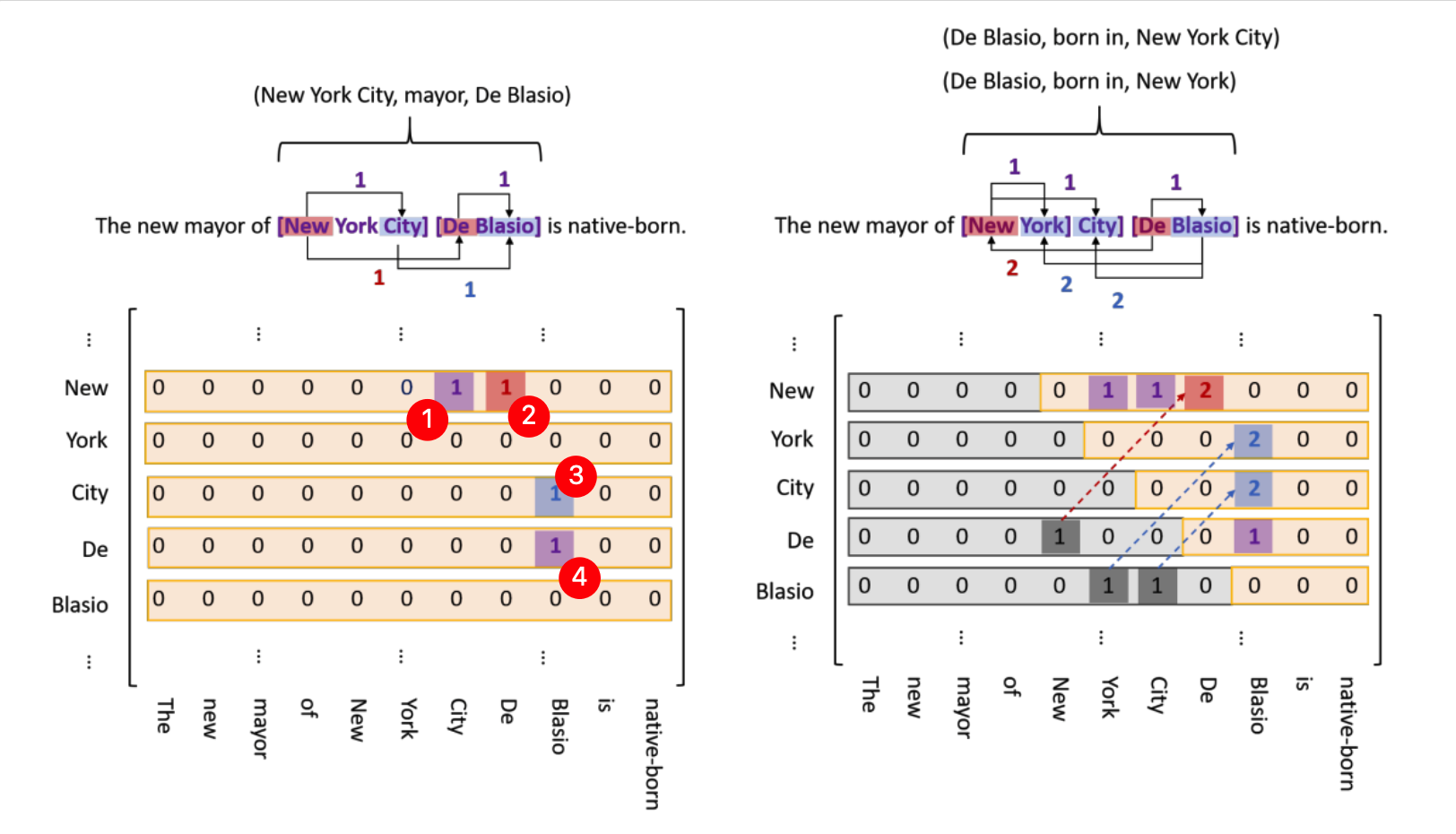
TPLinker 的具体的标注方式如下图所示。先看下图左侧部分,列表示开头,行表示结尾,紫色方框表示实体,红色方框表示两个实体头指针的关联,蓝色方框表示两个实体尾指针的关联。为了方便说明,在截图时添加了圆形红底白字的数字标记。在下图所示的样例中关系三元组为 ("New York City", "mayor", "De Blasio")。"New York City" 是一个实体,所以在红圈1的位置是紫色方框1;"De Blasio" 也是一个实体,所以在红圈4的位置也是紫色方框1;两个实体的头是单词 "New" 与单词 "De",所以在红圈2的位置是红色方框1;两个实体的尾是单词 "City" 和单词 "Blasio",所以在红圈3的位置是蓝色方框1。
注意,在下图中把 "实体开头到实体结尾"(entity head to entity tail (EH-to-ET))、"Subject实体的头到Object实体的头"(subject head to object head(SH-to-OH))、"Subject实体的尾到Object实体的尾"(subject tail to object tail(ST-to-OT))这三种类型都画到同一个图里了。这个只是为了方便说明,在实际编码时:
- EH-to-ET 对应一个矩阵;(实体是没有类型的)
- 每个关系类型的 SH-to-OH 对应一个矩阵;
- 每个关系类型的 ST-to-OT 对应一个矩阵;
所以总共是 (2 * 关系类型个数 + 1) 个矩阵。
下图的右侧是为了减小矩阵的大小做的优化。由于相对于文本的长度,文本中的实体、关系个数是非常少的,所以矩阵肯定是一个稀疏矩阵,所以考虑能否减小该矩阵。可以想到下面左图中的下三角矩阵和上三角矩阵是对称的,只是表示两个单词的指向方向不同。所以去掉下三角矩阵,只保留上三角矩阵,并且如果是从前指向后,矩阵中的值为1;如果是从后指向前,矩阵中的值为2;
3.2 解码方式#
比较简单,略。
3.3 显存分析#
相比于序列标注的方式,TPLinker 的显存消耗是相当大的。下面直接对着代码看一下其显存的消耗。
TPLinker 的模型整体结构为先是使用 BERT 模型做编码,然后组合出一个 (seq_len, seq_len, hidden_size) 的矩阵,最后将该矩阵过分类器,就能够得到 (seq_len, seq_len, class_num) 的结果了,这个就可以和标注结果计算loss了。
在下述代码中把 "使用 BERT 模型做编码" 和 "组合出一个 (seq_len, seq_len, hidden_size) 的矩阵" 这两部分的代码省略了,仅保留了分类器部分的代码。
由第 3.1 小节的描述可知,对于一条数据,标注结果编码之后是 (2 * 关系类型个数 + 1) 个矩阵,每个矩阵的大小是 (文本长度 * 文本长度);再考虑上每个批次中会有多条样本,那么每个批次的标签对应的矩阵的shape为:[batch_size, seq_len, seq_len, 2 * rel_size + 1]。
然后再看模型前向传播过程时,产生的中间矩阵的大小,这个在下述代码的注释里写的很清晰。在整个前向传播中几个主要阶段的中间结果维度:
- "使用 BERT 模型做编码" 之后获得的中间结果维度:[batch_size, seq_len, hidden_size]
- "组合出一个 (seq_len, seq_len, hidden_size) 的矩阵" 之后,这个矩阵的维度:[batch_size, seq_len, seq_len, hidden_size]
- "经过分类器进行分类" 之后得到的矩阵维度:[batch_size, seq_len, seq_len, class_num]
可以看出上述这三个中间过程的结果中,占据显存最多的是第2步产生的矩阵,维度为 [batch_size, seq_len, seq_len, hidden_size],在下述代码的注释中也给出了对该矩阵消耗显存的估计,当 batch_size=8,seq_len=512,hidden_size=768 时大概要消耗 6G 的显存。
所以整体来说 TPLinker 对显存的消耗是比较大的。
class TPLinkerBert(nn.Module):
def __init__(self, ...):
... ...
self.ent_fc = nn.Linear(hidden_size, 2)
self.head_rel_fc_list = [nn.Linear(hidden_size, 3) for _ in range(rel_size)]
self.tail_rel_fc_list = [nn.Linear(hidden_size, 3) for _ in range(rel_size)]
def forward(self, ...):
... ...
# 经过分类器之前的 shaking_hiddens4ent 和 shaking_hiddens4rel 的维度为:
# [batch_size, seq_len, seq_len, hidden_size]
# 假设 batch_size=8,seq_len=512,hidden_size=768,估计一下该矩阵的参数量:8 * 512 * 512 * 768 = 1.5B
# 单就这一个矩阵消耗的显存:如果用 fp32 训练就是 6G,如果用 fp16 训练就是 3G
ent_shaking_outputs = self.ent_fc(shaking_hiddens4ent)
head_rel_shaking_outputs_list = []
for fc in self.head_rel_fc_list:
head_rel_shaking_outputs_list.append(fc(shaking_hiddens4rel))
tail_rel_shaking_outputs_list = []
for fc in self.tail_rel_fc_list:
tail_rel_shaking_outputs_list.append(fc(shaking_hiddens4rel))
head_rel_shaking_outputs = torch.stack(head_rel_shaking_outputs_list, dim = 1)
tail_rel_shaking_outputs = torch.stack(tail_rel_shaking_outputs_list, dim = 1)
# 经过分类器之后,这三个返回值的维度为:
# [batch_size, seq_len, seq_len, 2]
# [batch_size, seq_len, seq_len, rel_size, 3]
# [batch_size, seq_len, seq_len, rel_size, 3]
# 如果忽略掉实体部分是二分类,关系部分是三分类这个区别,那么总的矩阵大小约为:
# [batch_size, seq_len, seq_len, 2 * rel_size + 1, class_num]
return ent_shaking_outputs, head_rel_shaking_outputs, tail_rel_shaking_outputs