WizardLM: Evol-Instruct#
原文链接: https://arxiv.org/pdf/2304.12244.pdf
github链接: https://github.com/nlpxucan/WizardLM
本文的指令进化分为深度进化和广度进化。深度进化有以下五种:add constraints, deepening, concretizing, increase reasoning steps, complicate input。广度进化为:mutation,比如:基于给定的指令生成全新的指令。广度进化的目的是解决指令数据集中主题缺乏多样性的问题,增加数据集的丰富度。
指令的进化是调用 LLM 来进行的,所以新生成的指令有可能是有问题的,所以对于生成的指令还会进行一个进化消除(Elimination Evolving)的操作,目的是去掉那些新生成的有问题的指令。
初始启动时使用的是 Alpaca 的初始数据,即 175 条人工编写的数据,使用 Evol-Instruct 方法获得 250k 指令,采样出 70k 的指令进行训练,训练的模型称为 WizardLM。对比的模型是 Alpaca、Vicuna、ChatGPT。评估时使用的数据集是人工构造的一份新的数据集,该数据集中简单和困难的指令都有,名字为 Evol-Instruct 测试集。
1、指令进化的具体操作#
分为以下三个步骤:
- 指令进化
- 生成response
- 进化消除
1.1 指令进化#
指令进化时的一些原则:
- 进化后的指令必须是合理的、人能够理解、并且人能够对该指令写出response。
- 指令的难度应该逐步增加,保证整个指令池中简单、中等、困难的指令数量是相对均衡的。
- 对于深度进化,为了限制难度的增加,限制每次进化指令最多增加10到20个单词。
- 对于广度进化,会要求其生成的指令的难度与原始指令是基本相同的。
各个深度进化和广度进化使用的具体指令在本文的最后面,或者直接去 论文原文 中查找也可以。
1.2 生成response#
这个操作就非常常规了,略。
1.3 进化消除#
按照以下四种方式进行进化消除:
- 使用 ChatGPT 判断新生成的指令与原指令相比是否有新的信息,调用 ChatGPT 的指令如下:
Here are two Instructions to ChatGPT AI, do you think they are equal to each other, which meet the following requirements:
1. They have same constraints and requirments.
2. They have same depth and breadth of the inquiry.
The First Prompt: <Here is first instruction.>
The Second Prompt: <Here is second instruction.>
Your Judgement (Just answer: Equal or Not Equal. No need to explain the reason.):
-
对进化后的指令使用 LLM 很难生成 response,比如生成的 response 中包含 "抱歉" 或者生成的 response 长度较短(少于80个词),对这种指令做进化消除。
-
新生成的指令中仅包含标点符号、停用词等内容时,对这种指令做进化消除。
-
新生成的指令中明显包含了进化指令中的内容时,比如包含 "given prompt"、"rewritten prompt"、"#Rewritten Prompt#" 等,对这种指令做进化消除。
1.4 多轮迭代进化的说明#
在多轮迭代时,每一轮都有一个独立的指令池,在迭代时仅使用上一轮迭代的指令池中的指令,不会再使用更前轮次的指令。下面使用符号对这部分进行说明。
初始人工构建的种子指令池使用符号 D^{(0)} 表示,第一轮时从 D^{(0)} 随机选择指令生成新的指令,新生成的指令放到 D^{(1)}。在第二轮时则从 D^{(1)} 中随机选择指令,用于生成新的指令,在该轮中不会再从 D^{(0)} 中选取指令了,新生成的指令放到 D^{(2)} 中。如此循环重复。
在最终训练时直接把所有的 D^{(0)}、D^{(1)}、...、D^{(N)} 都混合到一起进行训练。
之所以采用上述做法的目的是:每个指令池对应一个难度,只要每个指令池中的指令数量基本相同,那么上述这种做法就能够最大程度的保证不同难度的指令的均匀分布。
2、实验结果#
2.1 评估数据集分析#
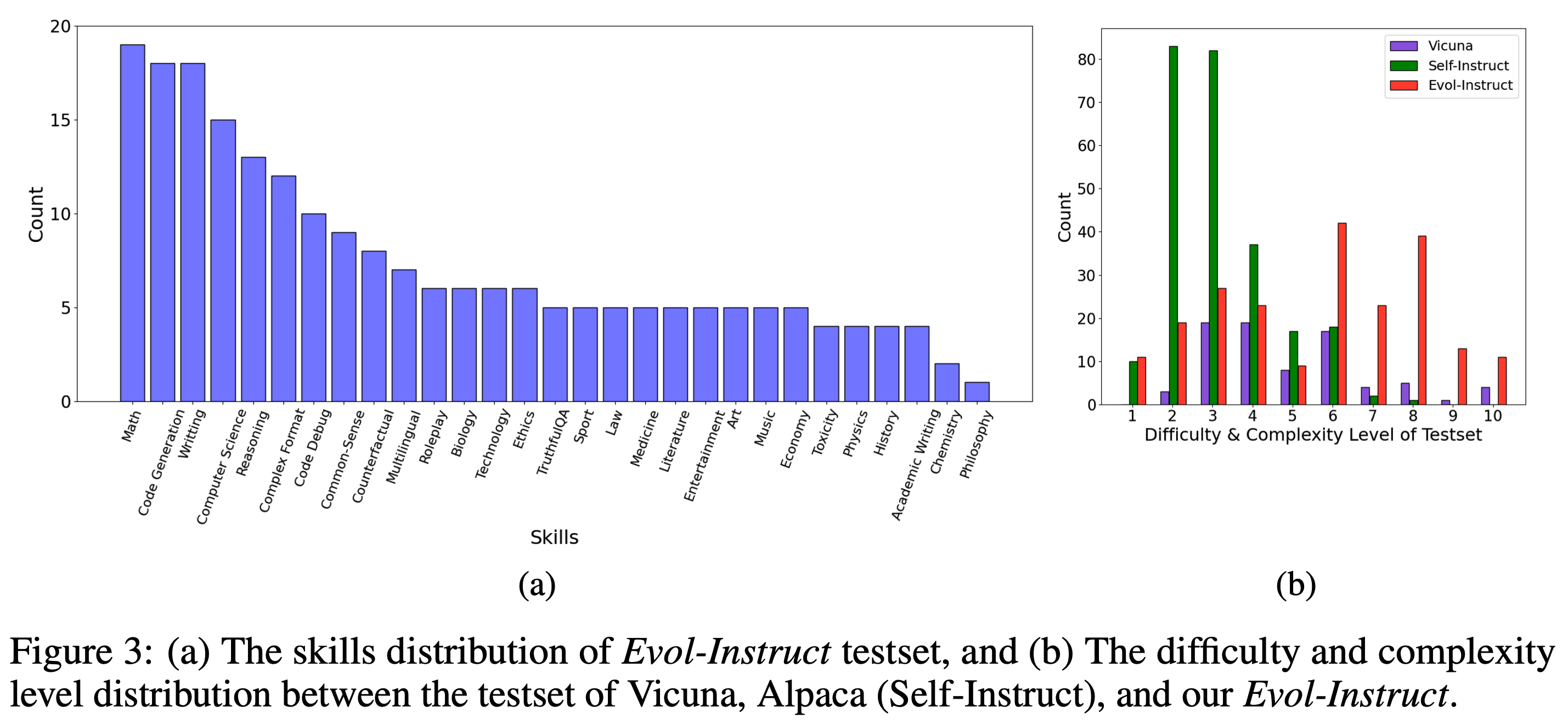
下图左侧是 Evol-Instruct 测试集中各个 topic 对应的数据量,总共29个 topic。下图右侧是 Alpaca 的测试集、Vicuna 的测试集、以及本文的 Evol-Instruct 测试集中,各种不同难度的数据的数量。本文的 Evol-Instruct 测试集中包含了更多的 topic,更具多样性。同时相对来说较难的指令占比更多。
2.2 人工评估#
总共10个标注人员,每个指令每人看到四个分别来自于 Alpaca、Vicuna-7b、WizardLM、ChatGPT 输出结果,顺序是打乱的,然后人工进行标注。评估结果如下图所示,绿色表示本文的模型效果更好,黄色表示本文的模型更差,紫色表示两个模型效果持平。可以得到如下一些结论:
-
相比于 Alpaca、Vicuna-7b,在下述三个测试集上都是 WizardLM 更好一些,尤其是在复杂测试集上,好的更多一些;
-
在复杂测试集上 WizardLM 比 ChatGPT 还要好一些;(这个结论当使用 GPT4 作评估时是相反的)

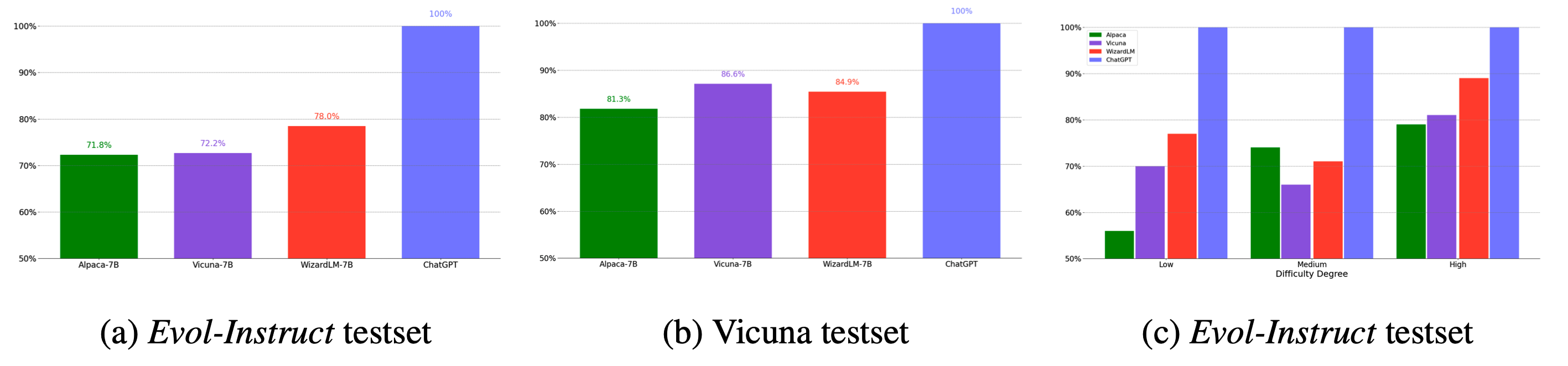
2.3 GPT4评估#
下图是GPT4评估的结果,其中绿色是 Alpaca 模型、紫色是 Vicuna 模型、红色是本文的 WizardLM 模型、蓝色是 ChatGPT 模型。
-
可以看出在 Evol-Instruct 测试集上本文的模型 WizardLM 是最优的;在 Vicuna 的测试集上,本文的 WizardLM 则比 Vicuna 模型略逊一些;
-
在 Evol-Instruct 测试集不同难度的样本上模型效果为图(c),可以看到在困难样本上本文的 WizardLM 模型要比 ChatGPT 模型效果差一些(这个结果和上面的人工评估结果是相反的)。人工标注结果和 GPT4 的标注结果出现了不一致。
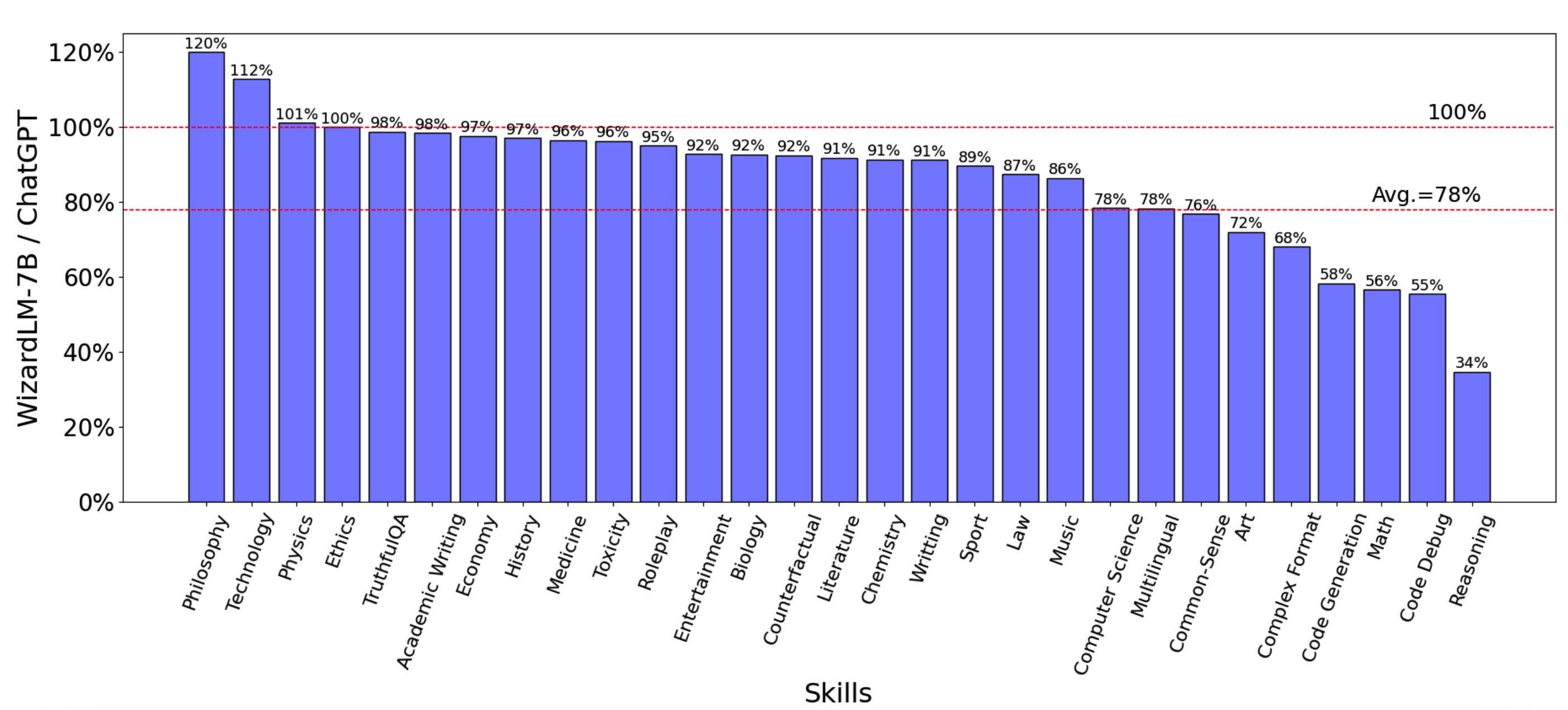
下图是使用GPT4对本文的 WizardLM 模型与 ChatGPT 模型在各个 topic 上的效果对比。可以看出在 22 个 topic 上本文的 WizardLM 模型能够达到 ChatGPT 的 78% 的效果。
3、进化指令详情#
5个深度进化的指令和1个广度进化的指令。
Add Constraints Prompt#

Deepening Prompt#

Concretizing Prompt#

Increased Reasoning Steps Prompt#

Complicate Input Prompt#
由于需要放样例,所以该指令比较长,如下述截图:
 |
 |
 |
 |
Breadth Evolving#
