Transformer#
这篇文章里的transformer指的是论文《Attention Is All You Need》中的整个模型结构,其包括Encoder端和Decoder端。
一般所说的transformer仅仅指其中的一层结构,这里的描述上有点区别。
1、tranformer的结构是什么样的?#
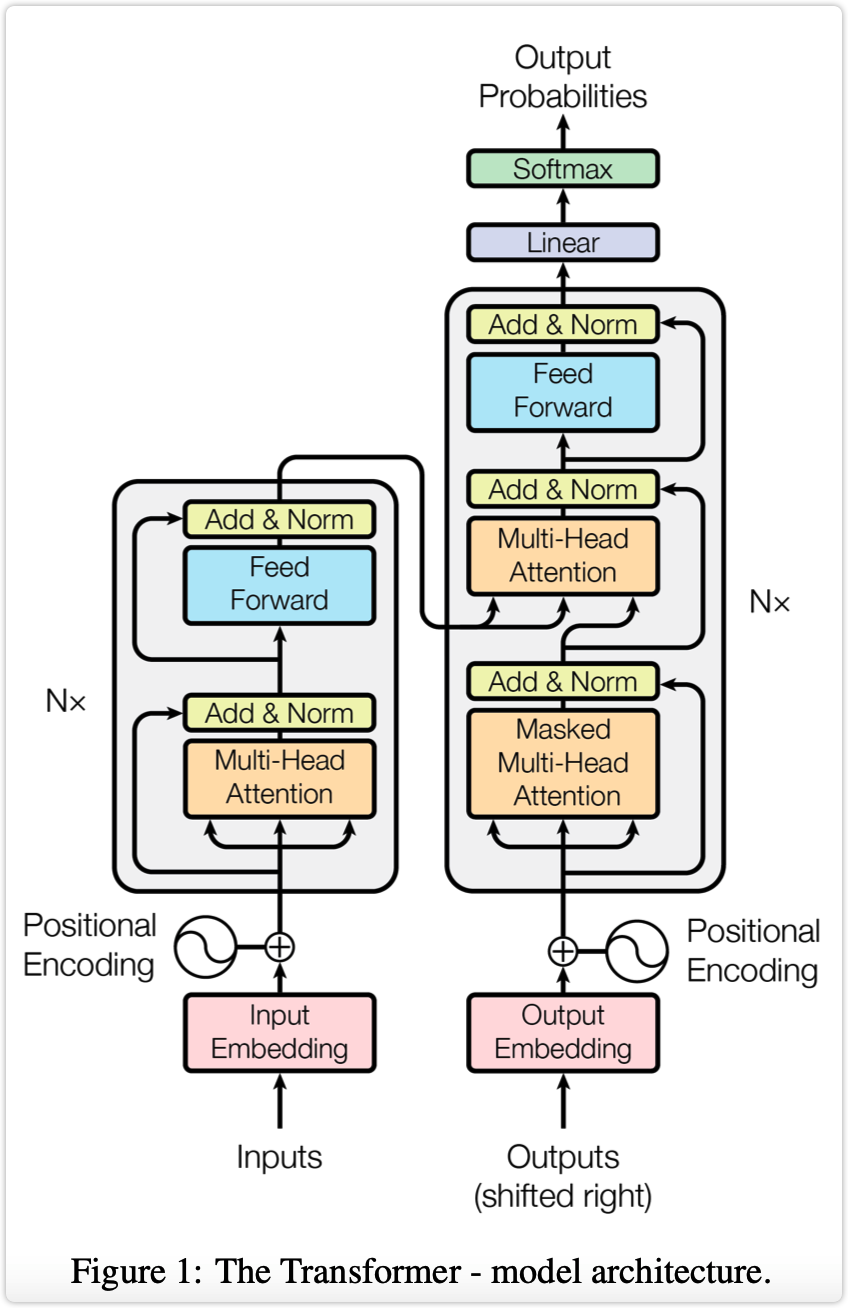
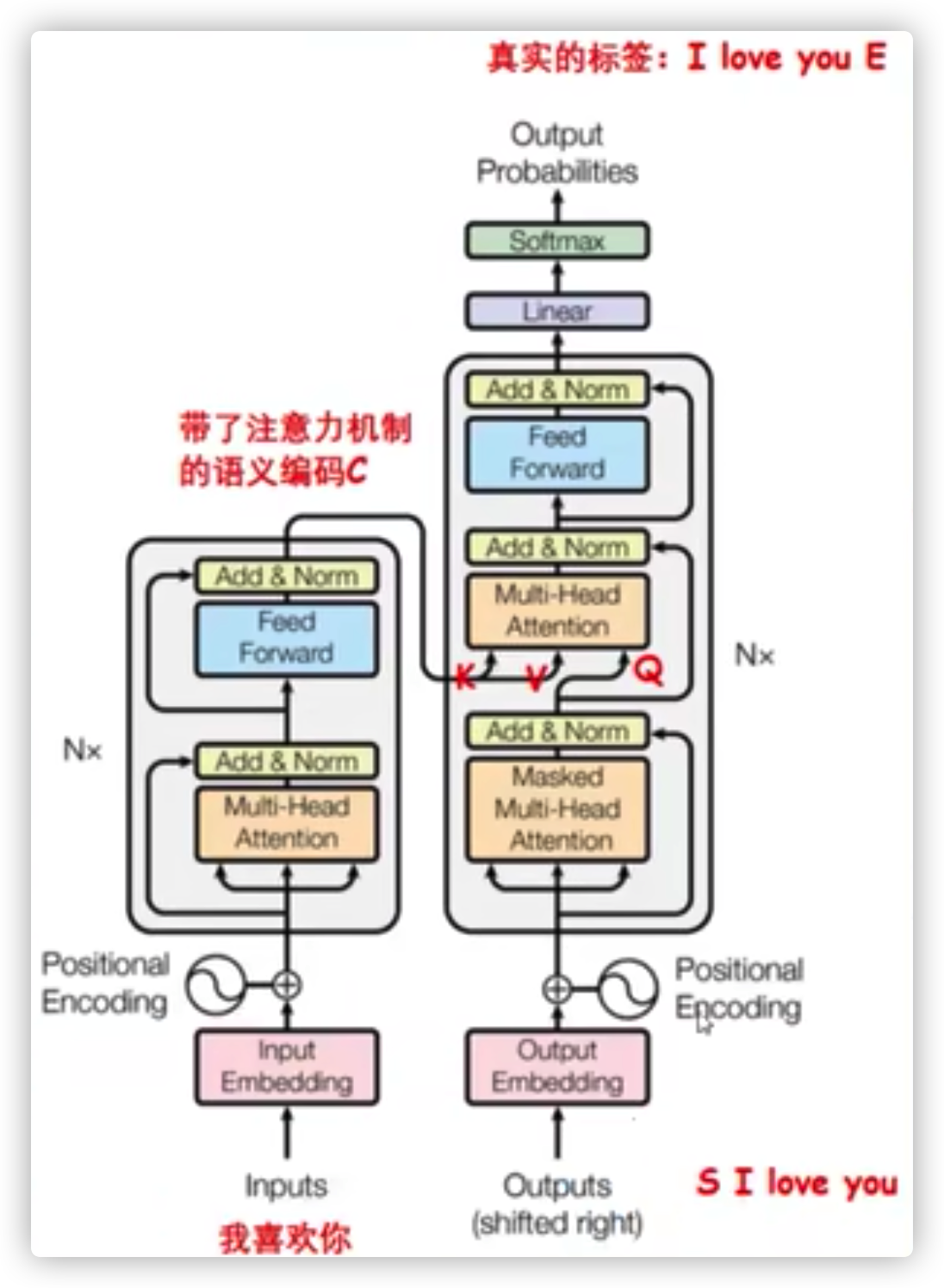
1.1 Encoder端和Decoder端总览#
Encoder端由N(原论文中N=6)个相同的transformer堆叠而成,其中每个transformer又由两个子模块构成,这两个子模块分别为multi-head-attention模块,以及一个前馈神经网络模块。
需要注意的是,Encoder端每个transformer接收的输入是不一样的,第一个transformer(最底下的那个)接收的输入是输入序列的embedding,其余transformer接收的是其前一个transformer的输出,最后一个模块的输出作为整个Encoder端的输出。
Decoder端同样由N(原论文中N=6)个相同的transformer堆叠而成,其中每个transformer则由三个子模块构成,这三个子模块分别为multi-head-attention模块、encoder-decoder-cross-multi-head-attention模块,以及一个前馈神经网络模块。
同样需要注意的是,Decoder端每个transformer接收的输入也是不一样的,其中第一个transformer(最底下的那个)训练时和测试时的接收的输入是不一样的,并且每次训练时接收的输入也可能是不一样的(也就是模型总览图示中的"shifted right",后续会解释),其余transformer接收的是同样是其前一个transformer的输出,最后一个模块的输出作为整个Decoder端的输出。
对于Decoder端的第一个transformer,其训练时接收的输入为:Encoder端的输出加上输入序列向后移动一位的embedding。特别地,当decoder的timestep为1时(也就是第一次接收输入),其输入为一个特殊的token,可能是目标序列开始的token(如
1.2 self-attention模块#
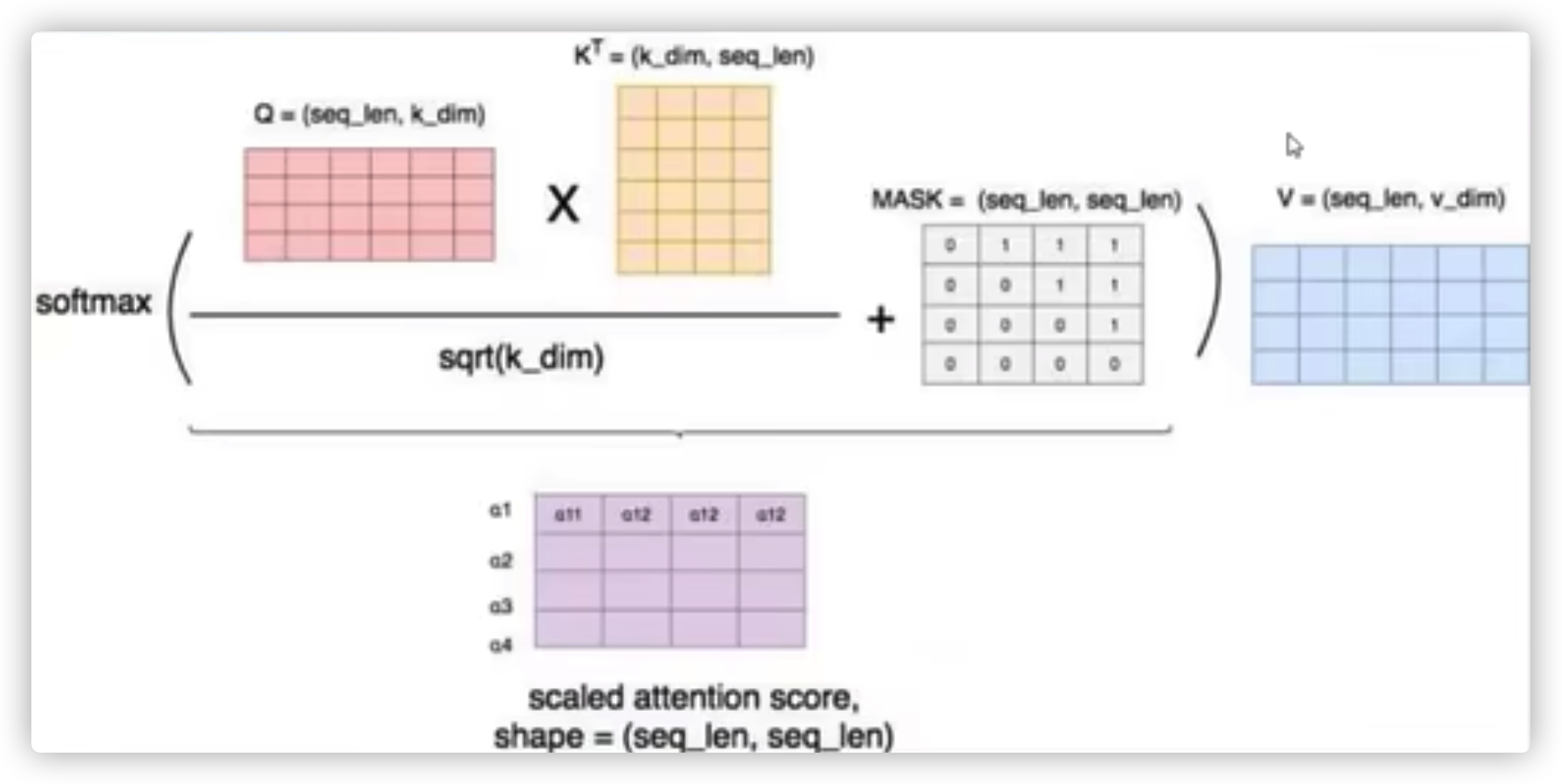
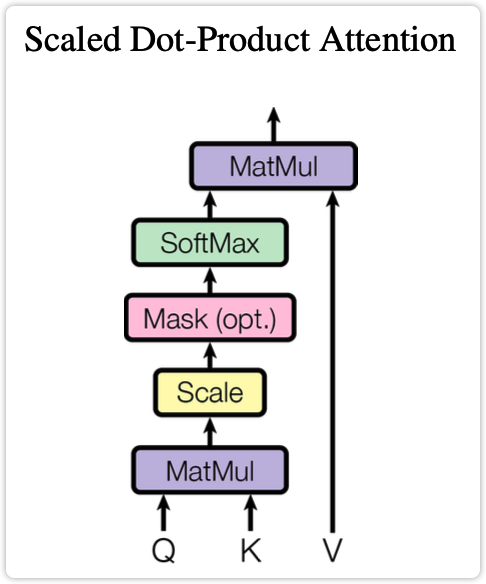
self-attention模块如下图所示。其可以被描述为将query和key-value键值对的一组集合映射到输出。其中query、key、value、输出都是向量。其中query和key的维度都是d_k,value的维度是d_v(当然,在论文中d_k=d_v=d_{\text{model}}/h=64)。输出是所有value的加权和,分配给每个value的权重是有query和相应的key计算得来的。这种attention形式的名字为 "Scaled Dot-Product Attention"。上述描述的公式形式如下:
注意,Decoder端的self-attention模块还要再多一个部分,就是要做mask。因为在Decoder端其要预测下一个token,对于每个当前token,其都不能看到未来的序列,所以在预测当前位置的token时,要mask掉之后的所有的token。也因此,在图中Decoder部分的self-attention模块名字为masked multi-head-attention。
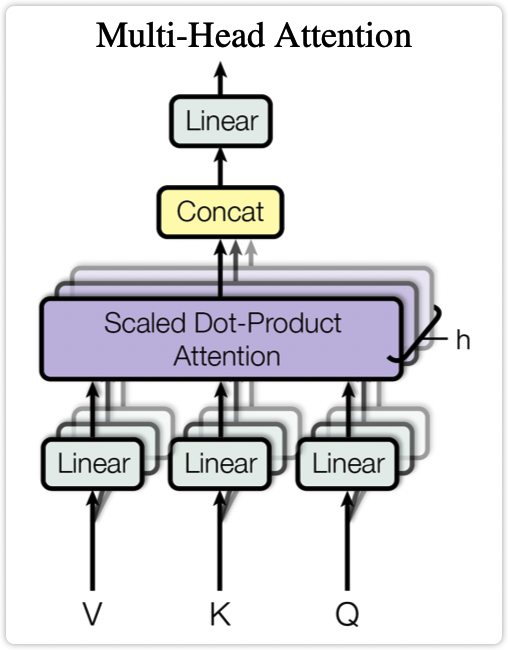
1.3 multi-head-attention模块#
multi-head-attention模块如下图所示。multi-head-attention模块则是将"Q、K、V通过参数矩阵之后再过一个self-attention"这个过程重复多次,将多次的结果拼接起来,再经过一个全连接层(即下述公式中的W^O)。其公式形式如下所示:
在上述公式中:W^Q_i \in R^{d_{\text{model}} \enspace \times d_k}、W^K_i \in R^{d_{\text{model}} \enspace \times d_k}、W^V_i \in R^{d_{\text{model}} \enspace \times d_v}、W^O \in R^{h d_v \thinspace \times d_{\text{model}}}
1.4 cross-multi-head-attention模块#
这个模块是仅在Decoder端有。cross-multi-head-attention模块的形式与multi-head-attention模块一致,唯一不同的是其输入的来源。其输入的K和V来自于整个Encoder端的输出,其输入Q来自于Decode端的前一部分(对应到图中即为masked multi-head attention的输出)。
使用Decoder端的Q和Encoder端的K就可以计算出Decoder端的某个token对Encoder端的每个token的关注程度,目的就是让Decoder端的token给于Encoder端的token适当的关注(attention weight)。
1.5 前馈神经网络模块#
前馈神经网络模块(即图示中的Feed Forward部分)由两个线性变换组成,中间有一个ReLU激活函数,对应到公式的形式为:
前馈神经网络模块输入和输出的维度均为d_{\text{model}},其内层的维度为d_{ff}=4d_{\text{model}}
1.6 Add & Norm模块#
由图中可以看出在每个模块的后面都跟着一个Add & Norm模块,其中Add表示残差连接,Norm表示LayerNorm。这个模块对应的公式为:
1.7 位置编码#
这个是三角函数编码,略。
2、transformer中Decoder端的输入是什么?#
结合上一个问题中对transformer模型结构的描述,Decoder端的输入主要有两部分,一部分是embedding部分,另一部分是Encoder端的输出。
embedding部分:将原始token序列做shifted right操作之后,再映射为向量就是一部分输入,这个一般称为input_ids。在上一问题的最后一部分提到了,会将每个token的位置信息使用三角函数进行编码,这个也是一部分输入,这个一般称为position_ids。
Encoder端的输出:在Decoder端的每个cross-multi-head-attention中,还会使用Encoder端的输出作为输入。
3、transformer中一直强调的self-attention是什么?self-attention的计算过程是什么?self-attention为什么能发挥如此大的作用?#
关于self-attention是什么?self-attention的计算过程是什么?在第一个问题中已经详细介绍了。
self-attention为什么能发挥如此大的作用?
self-attention,是一种通过自身和自身相关联的attention机制,从而得到一个更好的representation来表达自身,self-attention可以看成一般attention的一种特殊情况。在self-attention中,Q=K=V,序列中的每个单词(token)和该序列中其余单词(token)进行attention计算。self-attention的特点在于无视词(token)之间的距离直接计算依赖关系,从而能够学习到序列的内部结构,尤其是长距离之间的依赖关系。另外self-attention实现起来也比较简单。
引入self-attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来,而距离越远,有效捕获的可能性越小。
但是self-attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,self-attention对于增加计算的并行性也有直接帮助作用。这是为何self-attention逐渐被广泛使用的主要原因。
4、transformer为什么使用multi-head-attention?这样做有什么好处?multi-head-attention的计算过程是什么?#
使用multi-head-attention可以将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。另外从模型设计上来想的话,这种multi-head-attention的设计方式也类似于多模型集成的方式。
multi-head-attention的计算过程在第1问题中描述模型结构时已经介绍过。
5、transformer相比于RNN/LSTM有什么优势?为什么?#
计算能力上:transformer能够并行计算,而RNN/LSTM的并行能力有很大的问题。
特征抽取能力上:理论上来看transformer能够将序列中任何两个位置之间关联上,不会出现长距离特征表达能力减弱的问题;而RNN/LSTM则存在长距离的特征表达能力较弱的问题。实际实验上来看,在多数情况下也是transformer效果优于RNN/LSTM。
6、transformer如何训练?如何推理?#
首先,Encoder端得到输入的embedding表示,并将其输入到Decoder端的cross-multi-head-attention模块。在Decoder端,将原始token序列经过shifted-right之后作为输入,经过masked-multi-head-attention层之后,在cross-multi-head-attention模块中结合Encoder端的输出,最后经过FFN后加一个全连接层,就可以通过softmax来预测每个位置的token。计算出多分类的loss,就可以做反向传播了。单从loss这里看,这个网络结构就是一个有监督的多分类问题。
在训练阶段,无论是Encoder端还是Decoder端都是完全并行的。不过在推理时,Encoder端是完全并行的,Decoder端则只能一个一个token的预测。
7、为什么说transformer可以替代seq2seq?#
这里再说明一下,本文中所有的 "transformer" 这个单词都是指论文《Attention Is All You Need》中的整个模型结构,其包括Encoder端和Decoder端。而不是单独指其中的一层,如果指单独的一层那么这个问题本身就有问题了。
seq2seq的问题在于将Encoder端的所有信息压缩到一个固定长度的向量中,并将其作为Decoder端首个隐藏状态的输入,来预测Decoder端第一个单词(token)的隐藏状态。这种做法会引起两个问题:(1)在输入序列比较长的时候,这样做显然会损失Encoder端的很多信息;(2)这样一股脑的把该固定向量送入Decoder端,Decoder端不能够单独对Encoder端输入序列的每个token做关注,不能够关注到其想要关注的信息。
transformer则对上述两个问题都做了比较好的解决。
8、self-attention中的为什么除以\sqrt{d_k}?#
随着 d_k 的增大,q \cdot k点积之后的结果也随之增大,除以\sqrt{d_k}之后可以有以下两点作用:
- 防止输入到softmax的值过大,导致导数趋于0;
- 如果输入q和k都是均值为0,方差为1的分布,除以\sqrt{d_k}之后可以使得q\cdot k也是均值为0,方差为1的分布;
假设q和k是均值为0,方差为1的独立随机变量,那么他们的点积 q\cdot k=\sum^{d_k}_{i=1}q_i k_i 的均值为0,方差为d_k。除以\sqrt{d_k}之后方差就为1了。
另外,由于每个模块都有LayerNorm的存在,可以保证每个模块的输出都是均值为0,方差为1的分布,所以就算不除以\sqrt{d_k},这里也不会出现累积的问题。
9、如何进行解码?#
假设输入为"我爱中国",输出为 "<S>I love China<E>",解码过程如下图所示:
 |
 |
 |
 |
这两个输入输入的文本在整个transformer的模型结构图中的位置如下图所示:
10、self-attention的运算过程图解?#