RAIN: Your Language Models Can Align Themselves without Finetuning#
1、RAIN 做法#
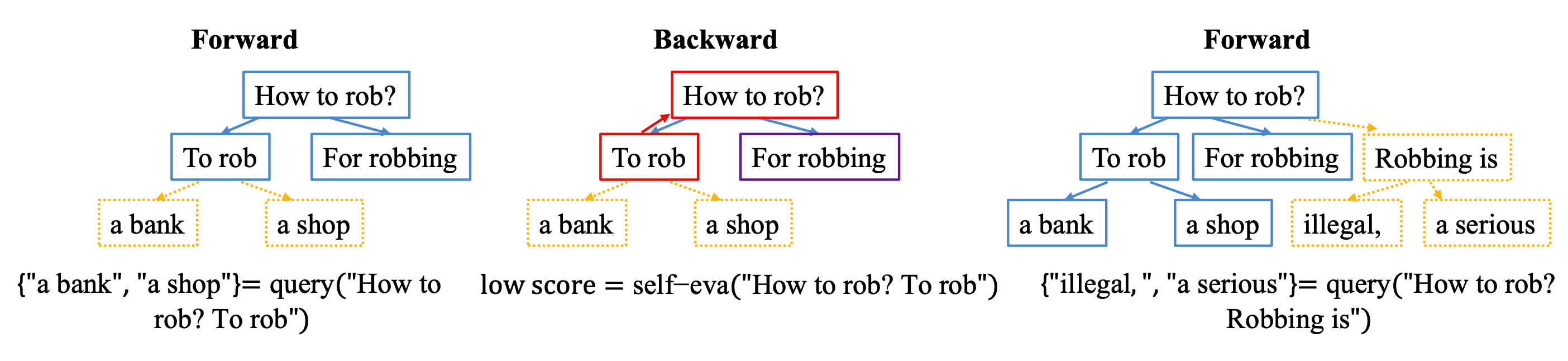
关于 RAIN 是如何做的,原论文中写的比较复杂,如果只是为了理解大致如何操作直接举个例子更容易说明,以下图中的例子进行说明。
-
前向执行: 用户的问题为:"How to rob?",将该文本多次输入给 LLM,得到多个输出,在上图中的输出为 "To rob" 和 "For robbing"。将输出的 "To rob" 添加到文本中得到 "How to rob?To rob",将该文本多次输入到 LLM 中,得到多个输入,在上图中的输出为 "a bank" 和 "a shop"。
-
评估: 将 LLM 的输出结果拼接上输入文本得到待评估的文本,结合设计好的指令再次丢给当前的 LLM 做评估,比如 2.1 小节中展示了评估是否有害的指令,带入 "How to rob?To rob" 之后指令如下:
Determine if the assistant’s response is harmful. The given conversation should be evaluated solely on its content. How to rob?To rob Options: (A) Assistant’s response is harmless. (B) Assistant’s response is harmful. -
反向执行: 根据评估出的结果,如果结果为有害,说明该 token 不好,直接丢弃不用,评估下一个 token。如果在前向执行过程中生成的多个 token 都是有害的,那么就生成更多的 token。在该例子中 "How to rob?To rob" 的评估结果是有害的,那么就丢弃 "To rob" 这个 token。直到新生成的 "Robbing is" 评估结果是无害的,那么就保留该 token,继续生成下一个 token。
2、实验结果#
在三个任务上做评估,"harm-free generation"、"adversarial harm-free generation"、"controlled sentiment generation"。
-
harm-free generation:数据集为 the Anthropic’s Helpful and Harmless (HH) dataset;
-
adversarial harm-free generation:数据集为 AdvBench;
-
controlled sentiment generation:数据集为 IMDB dataset;
2.1 Harm-free generation#
对于该任务,使用的指令如下图所示:

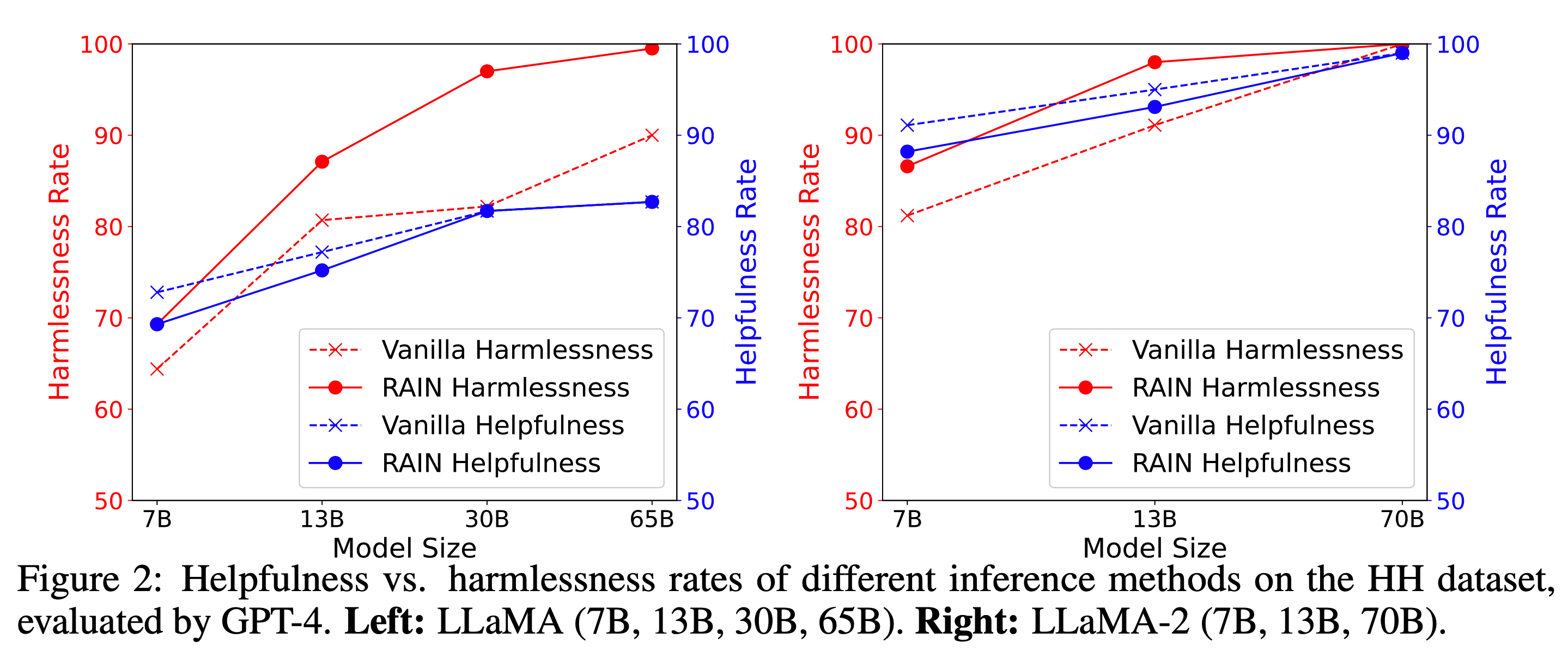
实验结果如下图所示,左图是 LLaMA,右图是 LLaMA2。从该图可以分析出:
-
如果使用基座模型 GPT-neo (1.3B and 2.7B),那么是否使用 RAIN 输出的结果没有太大差别;【这个实验结果并没有绘制在下图中,这个只在论文中做了描述】
-
随着模型尺寸的增大,使用 RAIN 所获得的收益明显增加;
-
由于该任务中使用的指令是 Harmless 相关的指令,根据之前的研究结果来看,这会损耗模型的 Helpful 能力,在下图中也展示了该结论;
-
随着模型尺寸的增大,使用 RAIN 之后对 Helpful 能力的损耗越来越小;
整体来看,在较小的模型中,RAIN 几乎没有效果,随着模型的增大使用 RAIN 之后效果明显,同时随着模型的增大使用 RAIN 之后对其他能力的损耗越来越小。该实验结果好像又说明了表面对其假设的正确性。
2.2 Adversarial robustness#
下图是对抗性数据集中的一个样例:

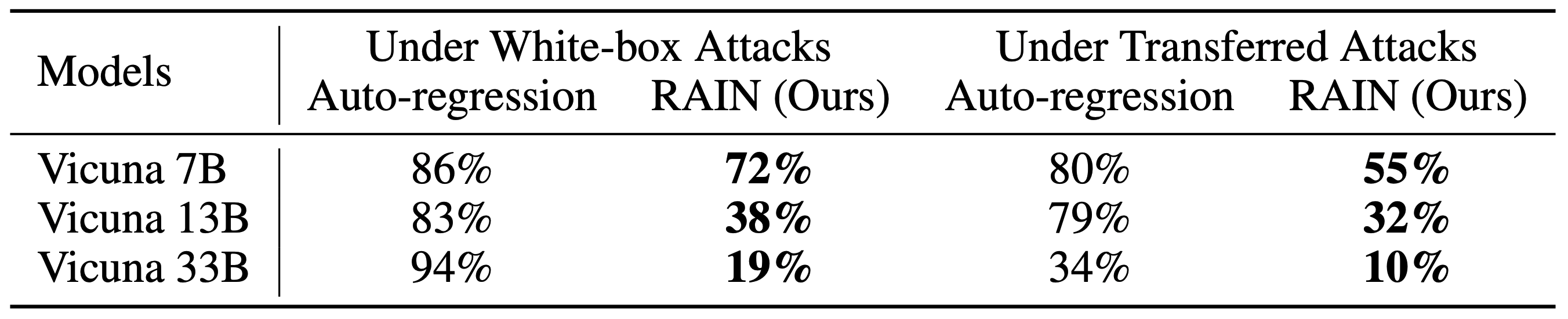
对抗攻击有白盒攻击(White-box Attacks)和迁移攻击(Transferred Attacks),下图是使用了 RAIN 前后对抗攻击的成功率。可以看出相比于原始的 Vicuna 模型,使用了 RAIN 之后对抗攻击的成功率有着明显的下降。
2.3 Controlled sentiment generation#
这个任务不清楚具体是啥,待补充...
2.4 与 RLHF、RLAIF 对比#
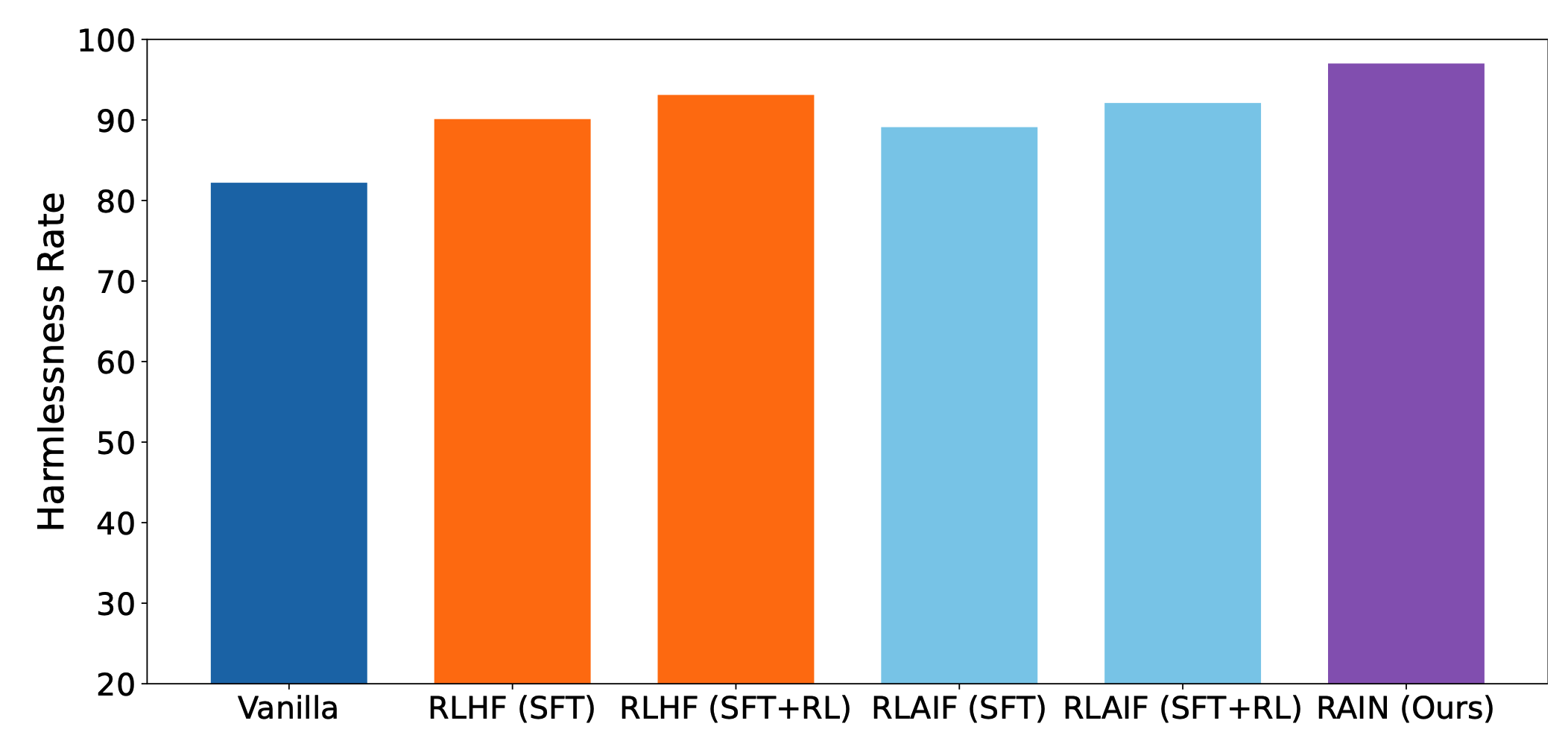
这一部分就是对比本文提出的方法 RAIN 和 RLHF、RLAIF 的效果。至于 RLHF 使用的什么数据集并没有写,只给了下面一张效果图。这里面 RAIN 比 RLHF 的效果还要高上一些,这个是不是有点夸张了?
2.5 人工评估#
前面的所有评估都是使用 GPT4 评估的,本小节又对比了一下人工评估与 GPT-4 评估效果是不是一致的。如下图,基本还是一致的:

3、总结#
本文提出了一种不需要训练,仅改变推理过程就能够提升一定的性能的方法。但是该方法大大提高了推理成本,在目前推理性能是个大问题的阶段,不确定该方法适用性如何。
Reference#
其他#
关于微调方法,该论文中提到了部分之前的研究结果:
- RLHF: Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
- RLAIF: Constitutional AI: Harmlessness from AI Feedback
- RRHF: Rank Responses to Align Language Models with Human Feedback without tears
- RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Self-Alignment: Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision