混合专家模型 (MoE)#
1、年份2017#
论文:outrageously large neural networks: the sparsely-gated mixture-of-experts layer
模型结构如下图所示:
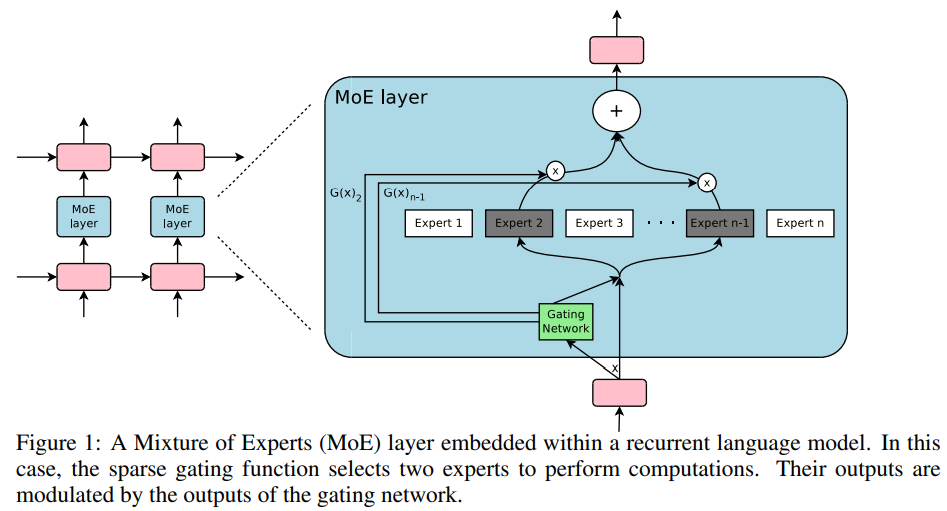
1.1 结构基础说明#
使用 E 表示上图中expert部分的网络,使用 G 表示上图中的门结构。向量 x 表示一个token对应的embedding的向量,为 MoE layer 部分的输入。
符号 G(x) 表示某个token经过门结构后的输出。符号 E_i(x) 表示该token经过第 i 个expert之后的输出。
那么 MoE layer 部分的输出结果为:
\begin{equation}y = \sum_{i=1}^{n} G(x)_iE_i(x)\end{equation}
在上式中 G(x) 中的每个元素都在[0,1]之间,并且所有的元素和为1,每个元素也就是 E_i(x) 的权重。
从该公式中很容易看出,当某个expert的 G(x)_i 为0时,那么输入向量 x 其实根本不需要经过该expert。所以门结构的输出 G(x) 才会在上图中使用了两次,上图中expert结构前使用 G(x) 的目的是筛选出向量 x 需要过哪些expert。上图中expert结构后使用 G(x) 的目的是按照公式(1)做加权求和。
1.2 Gate部分#
上图中的门结构最容易想到的是下式。即经过一个全连接层之后做softmax操作:
\begin{equation}G(x)=\text{softmax}(x \cdot W)\end{equation}
在本论文中还设计了一些其他的不同的门结构,见原论文。
2、Switch Transformers#
论文:Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity