ParameterServer#
1、DP#
2、DDP#
2.1 Ring AllReduce方法#
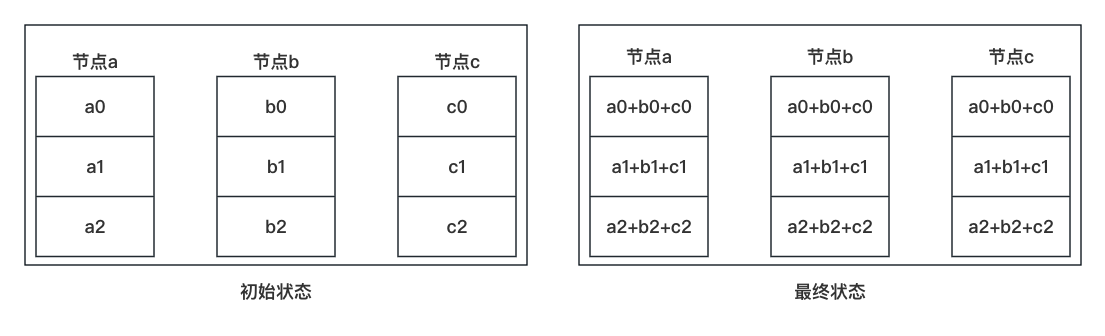
以三个GPU为例。如下图中的左图为例,将每个 GPU 上存储的梯度划分为三等份,也就是 a0、a1、a2、b0、b1、b2、c0、c1、c2 都是模型总梯度大小的 1/3。最终的目的是每个 GPU 上都有所有梯度之和,也就是如下图中的右图所示。
传输过程如下图所示。可以看出,这三等份中每一份的传输过程都是完全相同的,所以只分析其中的一份即可。在 Reduce 过程中,共传输了 2 次(也就是 3-1);在 AllGather 过程中,也传输了 2 次(也就是 3-1);每次传输的内容的大小为模型总梯度的 1/3。
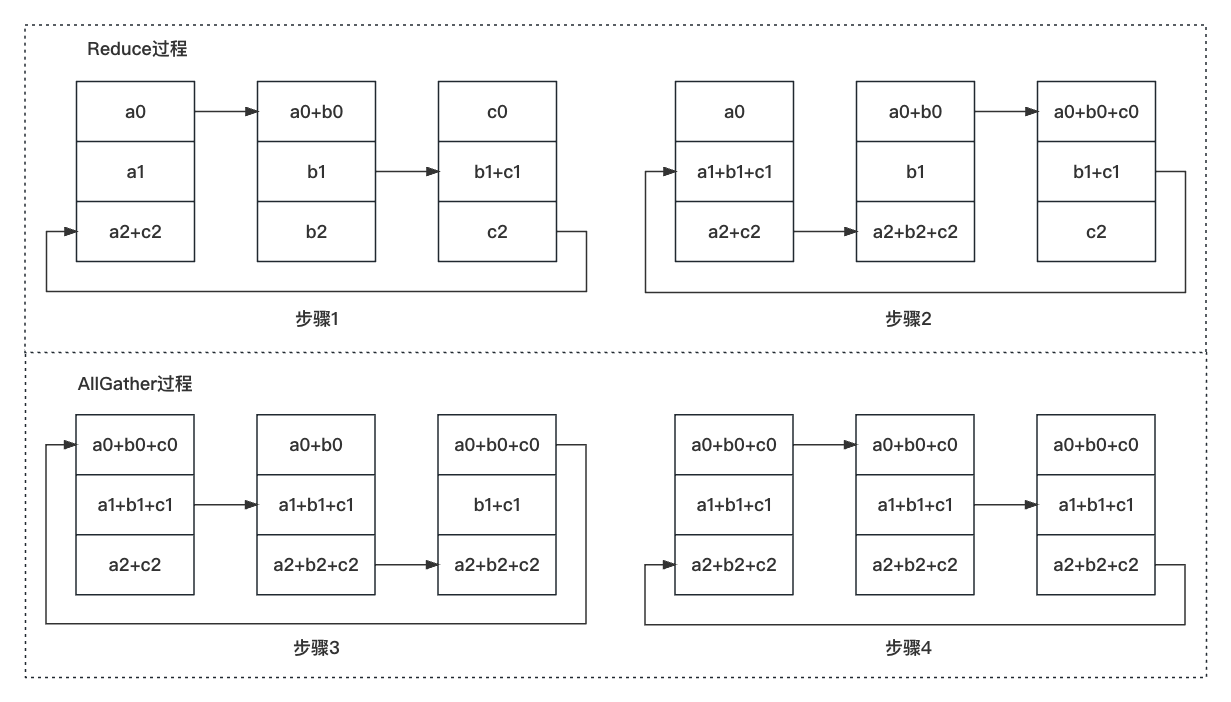
传输次数和传输量的分析:
我们记模型的参数量为 \Psi,那么梯度的参数量也为 \Psi,记显卡的数量为 N。那么 Reduce 过程会传输 N-1 次,AllGather 过程会传输 N-1 次,每次传输的内容大小为 \Psi/N。总共需传输 2(N-1) 次,总共需传输的参数量大小为 \Psi/N * 2(N-1)=2(\Psi - \Psi/N)。
当 N 的值比较大时,计算时会做一些近似,会将总共需传输的 2(N-1) 次近似为 2N 次。那么总共需传输的参数量大小为 \Psi/N * 2N = 2\Psi